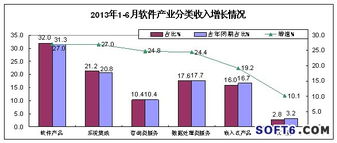
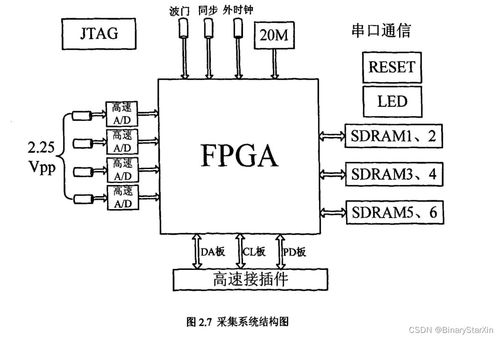
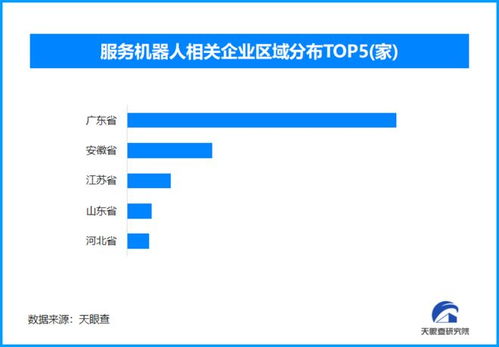
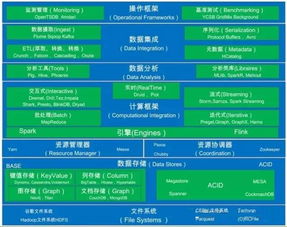
大数据处理系统是由大量服务器、高速网络和大规模存储设备构成的复杂基础设施,其数据处理和存储服务的开展遵循系统化的工作流程。
在数据处理方面,系统首先通过分布式采集技术从多样化数据源(如传感器、日志文件、数据库等)获取原始数据。数据进入系统后会经过清洗、转换和集成等预处理环节,以消除噪声并统一格式。核心处理阶段采用分布式计算框架(例如Hadoop MapReduce或Spark),将任务分解为多个子任务并行执行于集群节点上,显著提升处理效率。流处理引擎(如Flink或Storm)则支持实时数据分析,满足对即时洞察的需求。处理结果通过数据可视化工具或API接口交付给用户。
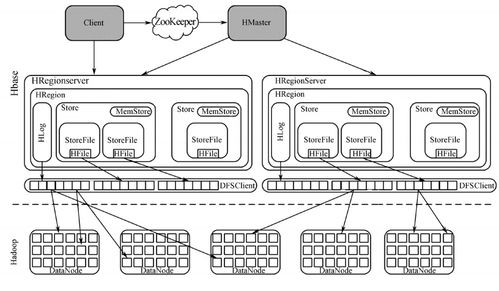
在存储服务方面,系统依赖分布式文件系统(如HDFS)或对象存储(如Amazon S3)来管理海量数据。这些存储方案通过数据分片和副本机制确保高可用性和容错性;数据通常根据访问频率被分层存储,冷数据移至成本较低的归档存储,而热数据保留在高速介质中。元数据管理系统跟踪数据位置与属性,便于快速检索。安全措施如加密和访问控制贯穿整个流程,保障数据隐私。
整体上,大数据系统的服务开展依赖于软硬件协同,通过自动化调度与监控工具优化资源利用,从而高效、可靠地支持企业决策与创新应用。