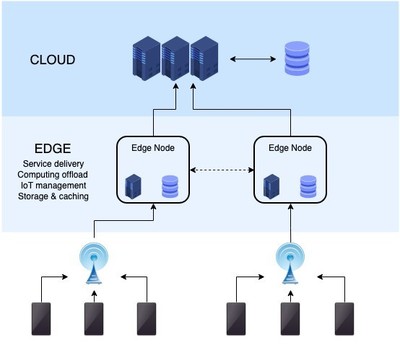
在物联网边缘计算架构中,Kafka作为高吞吐量的分布式消息系统,发挥了关键的数据处理和存储作用。其核心优势包括高吞吐、低延迟和分布式架构,特别适合应对物联网设备产生的海量数据流。
Kafka在边缘计算中的数据处理流程
- 数据采集与缓冲:边缘设备通过Kafka生产者API将实时数据(如传感器读数、设备状态)发布到Kafka主题。Kafka的持久化日志结构可作为数据缓冲区,有效缓解网络波动导致的数据丢失风险。
- 流式处理集成:结合Kafka Streams或KSQL,可在边缘节点直接实现数据过滤、聚合和转换。例如对温度传感器数据实时计算移动平均值,仅将异常结果上传至云端。
- 多级数据分发:通过Kafka Connect将数据同步到边缘数据库(如SQLite)或云存储(如S3),同时支持将关键数据转发至云端Kafka集群进行深度分析。
存储策略优化
- 分层存储配置:设置合理的日志保留策略,对实时数据保留24小时,重要数据通过压缩主题长期存储
- 数据序列化:采用Avro格式序列化数据,结合Schema Registry确保边缘与云端数据格式一致性
- 容灾机制:在边缘网关部署Kafka镜像节点,通过副本机制保障单点故障时的数据可用性
实践案例参考
某智能制造企业在产线边缘部署Kafka集群,每台机床通过MQTT-Kafka桥接器上报运行参数。边缘计算节点实时分析设备故障特征,当检测到异常振动模式时,立即通过Kafka消息触发本地告警,同时将精简后的诊断数据批量上传至云平台。这种架构使核心业务逻辑在边缘完成,带宽占用降低70%,故障响应时间从秒级优化至毫秒级。
注意事项
- 需根据边缘设备资源限制调整Kafka内存配置
- 建议使用轻量级Docker容器部署边缘Kafka节点
- 通过TLS加密和SASL认证保障边缘数据传输安全
通过合理运用Kafka的流处理能力和存储特性,物联网边缘计算可构建出兼具实时性、可靠性和可扩展性的数据处理体系。